Narzędzie do tworzenia pulpitów z interfejsami API ptaków
·

Najważniejsze informacje
Interfejsy API ptaków można połączyć z Pythonem i Plotly Dash, aby zbudować potężne, interaktywne pulpity nawigacyjne bez potrzeby korzystania z pełnego interfejsu użytkownika Bird.
Projekt pokazuje, jak wizualizować metryki i wydarzenia za pomocą interfejsu API metryk i interfejsu API zdarzeń Bird w niestandardowej aplikacji internetowej.
Plotly Dash zapewnia szybkie, otwarte źródło do budowania elementów interfejsu użytkownika, takich jak rozwijane listy, wykresy i tabele.
Deweloperzy mogą rozszerzać narzędzie o analizę dostarczalności, filtrowanie i paginację, aby uzyskać bogatsze pulpity nawigacyjne.
Przyszłe ulepszenia obejmują buforowanie, ulepszony interfejs użytkownika oraz integrację z innymi produktami Bird lub interfejsami API stron trzecich.
Baza kodu (dostępna na GitHub) stanowi mocny punkt wyjścia dla każdego, kto chce zbudować pulpity nawigacyjne oparte na Bird lub portale dla klientów.
Podsumowanie pytań i odpowiedzi
Jaki jest cel tego projektu dashboardowego?
Pokazuje, jak deweloperzy mogą korzystać z Bird APIs w Pythonie i Plotly Dash, aby tworzyć oparte na danych pulpitowe, które wizualizują metryki kampanii i ostatnie wydarzenia.
Dlaczego używać Plotly Dash do interfejsów API ptaków?
Dash jest open source, łatwy do dostosowania i idealny do tworzenia interaktywnych interfejsów użytkownika bez potrzeby posiadania wiedzy w zakresie front-endu.
Co wyświetla panel kontrolny?
Wizualizuje metryki czasowe z API Metryki Bird oraz dane o recentnych zdarzeniach z API Zdarzeń, z opcjami filtrowania i wybierania metryk w niestandardowych zakresach czasowych.
Jak można jeszcze bardziej rozszerzyć to narzędzie?
Poprzez dodanie analityki dostarczalności, zaawansowanych filtrów, cachowania danych oraz paginacji dla dużych zbiorów danych w celu poprawy wydajności i użyteczności.
Jakie umiejętności lub narzędzia są potrzebne do jej uruchomienia?
Podstawowa wiedza o Pythonie i instalacja bibliotek requests, dash oraz pandas. Klucz API z Bird jest wymagany, aby pobrać dane.
Jak ten projekt wpisuje się w ekosystem Birds?
Ilustruje, w jaki sposób otwarte interfejsy API Bird mogą być wykorzystywane do tworzenia niestandardowych pulpitów nawigacyjnych i narzędzi raportowych dla zespołów lub klientów, którzy nie mają dostępu do pełnej platformy.
Ten skrypt jedynie dotyka powierzchni tego, co jest możliwe dzięki wykorzystaniu Pythona, Plotly Dash i naszych interfejsów API.
API i pulpit nawigacyjny Bird Metrics z Pythonem
Prawie rok temu Tom Mairs, dyrektor ds. sukcesu klienta w firmie Bird, napisał narzędzie do przesyłania wiadomości wykorzystujące API Bird. W tym poście kontynuuję to, co on zaczął. Jego narzędzie umożliwia zdalne przesyłanie zadań w określonych odstępach czasu, ale co jeśli chcemy stworzyć nasze własne pulpity nawigacyjne i dzienniki zdarzeń?
Może chcę stworzyć konkretny pulpit nawigacyjny dla grupy biznesowej lub pulpit przyjazny dla klienta, ale nie chcę dawać użytkownikom pełnego dostępu do interfejsu UI Bird. Ten skrypt tylko dotyka powierzchni możliwości wykorzystania Pythona, Plotly Dash i naszych API. Tworząc pulpity, które przetwarzają dane API o dużym wolumenie, należy być świadomym, że komponenty infrastruktury, takie jak DNS, mogą stać się wąskimi gardłami - doświadczyliśmy wyzwań związanych ze skalowaniem DNS AWS, które wpłynęły na nasze możliwości przetwarzania danych. Dla entuzjastów wizualnych przepływów pracy, można również zbadać integrację Flow Buildera z Google Cloud Functions i Vision API, aby dodać automatyzację wspieraną przez AI do swoich przepływów przetwarzania danych.
Kiedy rozpocząłem moje poszukiwania w sieci, chciałem znaleźć drogę o jak najmniejszym oporze. Mógłbym stworzyć wszystkie pulpity i UI samodzielnie w HTML i Pythonie, jednak po kilku wyszukiwaniach w Google natknąłem się na Dash Plotly, który łatwo integruje się z Pythonem. Wybrałem Dash z dwóch powodów: 1) jest open source, a 2) po przeczytaniu dokumentacji wydawało się łatwo dostosowywać do tego, co próbowałem zrobić. Dash to biblioteka open-source, która jest idealna do budowania i wdrażania aplikacji danych z dostosowanymi interfejsami użytkownika. Dzięki temu stworzenie UI stało się niezwykle proste. Pytanie brzmiało więc, jak skomplikowaną chciałem uczynić tę aplikację? Im więcej czasu spędzałem, tym więcej funkcji chciałem dodać.
Dla wstępnego projektu chciałem upewnić się, że mam pulpit nawigacyjny z konfigurowalnymi metrykami i wybieranym zakresem czasowym. Na początku zacząłem od pulpitu, na którym można było wybrać tylko jedną metrykę z rozwijanej listy. Następnie, gdy otrzymałem opinie od kolegów, nieco dopracowałem pulpit, aby dodać możliwość wielokrotnego wyboru i tytuły osi. Postanowiłem także dodać dodatkową zakładkę na dziennik zdarzeń. Doszedłem do momentu, w którym byłem zadowolony z tego, co miałem jako dobry punkt wyjścia dla każdego, kto chciałby zbudować własne pulpity. Dla programistów, którzy chcą wprowadzać dane webhooków w czasie rzeczywistym do swoich pulpitów, zapoznaj się z naszym przewodnikiem po budowaniu konsumentów webhooków z Azure Functions. Oczywiście umieściłem projekt na Githubie, abyś mógł go sklonować lub utworzyć gałąź.
Pierwsze kroki
Aby uzyskać dostęp do tej aplikacji, musisz upewnić się, że używasz Pythona 3.10 lub nowszego oraz zainstalować następujące biblioteki:
Biblioteka Pythona | Cel |
|---|---|
requests | Komunikacja API z usługami Bird |
dash | Renderowanie interfejsu użytkownika i pulpitu nawigacyjnego |
pandas | Przetwarzanie danych i generowanie tabeli |
Następnie wprowadź swój klucz API do App.py i uruchom aplikację. Będzie działać pod adresem http://localhost:8050. Aby uzyskać więcej informacji na temat wdrażania tego na serwerze dostępnym publicznie (np. AWS), zobacz poniższe źródła:
Tworzenie strony pulpitu
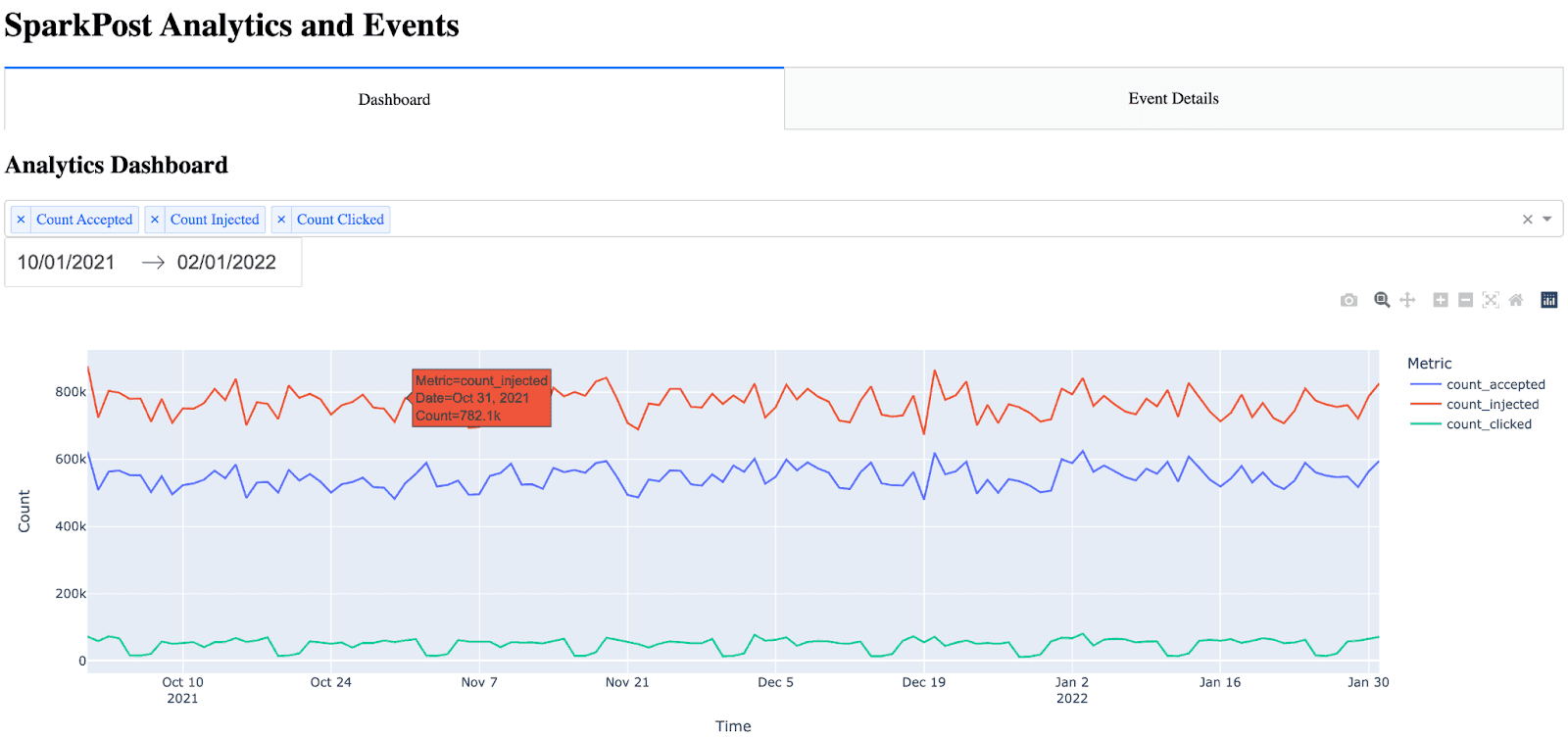
Tworzenie strony szczegółów wydarzenia
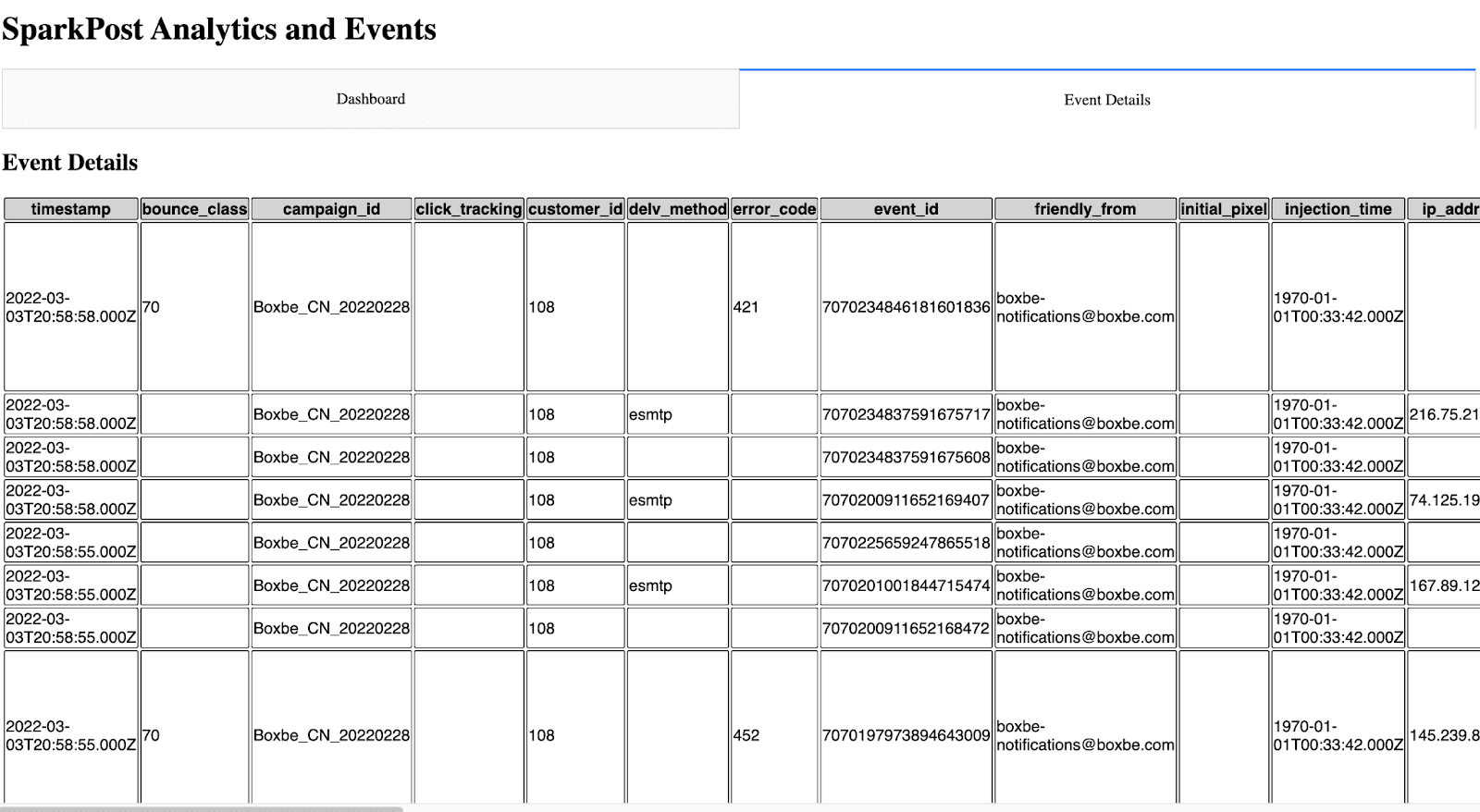
Następne kroki
Dla kogoś, kto chce stworzyć własny pulpit nawigacyjny lub dziennik zdarzeń, to dobry początek. Dzięki tej personalizacji, niebo jest limitem.
Jak wspomniano powyżej, niektóre przyszłe usprawnienia, które można wprowadzić, to:
Dodanie analizy dostarczalności do pulpitu nawigacyjnego
Dodanie większej liczby filtrów do pulpitu nawigacyjnego
Możliwe opcje buforowania, aby API nie było wywoływane za każdym razem przy wyświetlaniu stron
Ulepszenia interfejsu użytkownika
Dodanie filtrowania i paginacji na stronie szczegółów zdarzeń
Byłbym zainteresowany usłyszeniem wszelkich opinii lub sugestii dotyczących rozszerzenia tego projektu.
~ Zach Samuels, Starszy inżynier ds. rozwiązań w Bird



