Creating and Consuming Bird Webhooks
·
Jan 27, 2022

Key Takeaways
Bird’s real-time event webhooks let senders receive event data instantly—no polling, no cron jobs, and no rate-limit headaches.
Webhooks eliminate the complexity of managing time windows, preventing missed events and handling duplicate records.
Ideal for downstream automation: updating lists, starting journeys, enriching dashboards, or syncing internal systems.
The tutorial walks senders through building a full AWS ingestion pipeline: S3 storage, Lambda processing, and an application load balancer.
S3 serves as the central storage layer for webhook payloads, with each batch written as a flat JSON file.
Lambda functions handle both ingestion (storing raw batches) and transformation (converting JSON to CSV).
Bird batches events—each webhook batch includes a unique
x-messagesystems-batch-id, allowing replay checks and deduplication.The consumer Lambda must remain efficient since Bird retries batches if the endpoint does not respond within ~10 seconds.
AWS ALB is recommended (vs. API Gateway) for simplicity, cost-effectiveness, and direct handling of HTTP POST requests.
DNS (Route 53 or external provider) is configured to map a friendly hostname to the ALB endpoint.
After setup, Bird pushes event data directly and reliably to your AWS pipeline for asynchronous processing.
The guide also covers best practices: least-privilege IAM permissions, temp storage constraints, avoiding recursive triggers, and organizing multi-lambda workflows.
Q&A Highlights
What is the main purpose of Bird’s real-time event webhooks?
To push event data directly to a sender’s endpoint in real time, enabling immediate automation without polling or rate-limited API calls.
Why are webhooks better than pulling data via API for large senders?
Because API pulls require time-window management, risk data gaps or duplicates, and may hit rate limits—webhooks eliminate all of that by pushing data continuously.
What AWS services are used in the recommended webhook ingestion pipeline?
Amazon S3 (storage), AWS Lambda (processing), an Application Load Balancer (HTTP listener), and optionally Route 53 (DNS).
How does Bird batch event data?
Bird sends multiple events together in a payload, each assigned a unique batch ID (x-messagesystems-batch-id) for tracking, retries, and deduplication.
What triggers the consumer Lambda function?
The ALB forwards incoming webhook POST requests directly to the Lambda, which extracts the payload and writes it to S3.
Why store the raw webhook batch in S3 before processing it?
To ensure fast ingestion (<10 seconds) so the connection doesn’t timeout, and to offload heavier processing to a separate async pipeline.
What does the second Lambda function do?
It is triggered by new S3 objects, validates the JSON, converts it to CSV, and writes the processed output to a separate S3 bucket.
Why use a separate S3 bucket for processed CSV files?
To avoid recursive triggers (writing a new processed file back into the same bucket would re-trigger the Lambda endlessly).
What permissions do the Lambda functions require?
The consumer Lambda needs S3 PutObject permissions; the processing Lambda needs GetObject for the source bucket and PutObject for the destination bucket.
Why is an AWS ALB recommended over API Gateway?
ALBs are cheaper, simpler, and ideal for straightforward HTTPS POST forwarding; API Gateway may alter payload format and increase complexity.
How do senders configure the webhook in Bird?
By providing the HTTPS endpoint (the DNS record for the ALB), selecting a subaccount, choosing events, and saving the webhook configuration.
What downstream options exist for storing or analyzing the processed data?
Load into databases (PostgreSQL, DynamoDB, RDS), feed into ETL systems, or query directly with tools like Athena.
Bird’s real-time event webhooks are an incredibly valuable tool for senders to have data automatically pushed to their systems. This can drive downstream automation such as updating mailing lists, triggering automated email journeys, or populating internal dashboards. While the same event data can be accessed via the Bird UI using Event Search, or programmatically by leveraging the Bird Events API, limitations placed on the number of records returned in a single request or rate limits placed on the API endpoint can make both of these methods restrictive for large and sophisticated senders.
Real-time event webhooks enable a sender to configure an endpoint where Bird transmits the data to, and the data can be consumed without having to schedule cron jobs that pull the data. There are also logistical trade-offs when pulling the data as opposed to having the data pushed to you, such as having to identify what time period and parameters to use for each API request. If the time periods are not lined up perfectly then you risk missing data, and if the time periods overlap then you need to handle duplicate data records. With real-time webhooks, event data is simply pushed to your endpoint as it becomes available within Bird.
While the benefits of receiving event data in real-time to drive downstream automation processes may be immediately understood by many senders, the actual process for implementing and consuming webhooks may be intimidating. This can be especially true if you are unfamiliar with the technical components of creating an endpoint and handling the data programmatically. There are services available that will consume Bird webhook data and ETL into your database automatically – an example would be StitchData, which we have blogged about in the past. However, if you would like more control over the process you can easily build the components yourself. The following is a simple guide to help senders feel comfortable when creating a Bird events webhook and consuming the data using the infrastructure within AWS.
Configuring Webhook Target Endpoint
When a Bird event is created, we want that event data to be streamed in real-time to an endpoint in AWS so that we can consume and use that data programmatically. The data will be sent from Bird to a target endpoint, which will forward the payload to a lambda function that will process and store the data in an S3 bucket. A high-level diagram of the described data flow can be seen below:
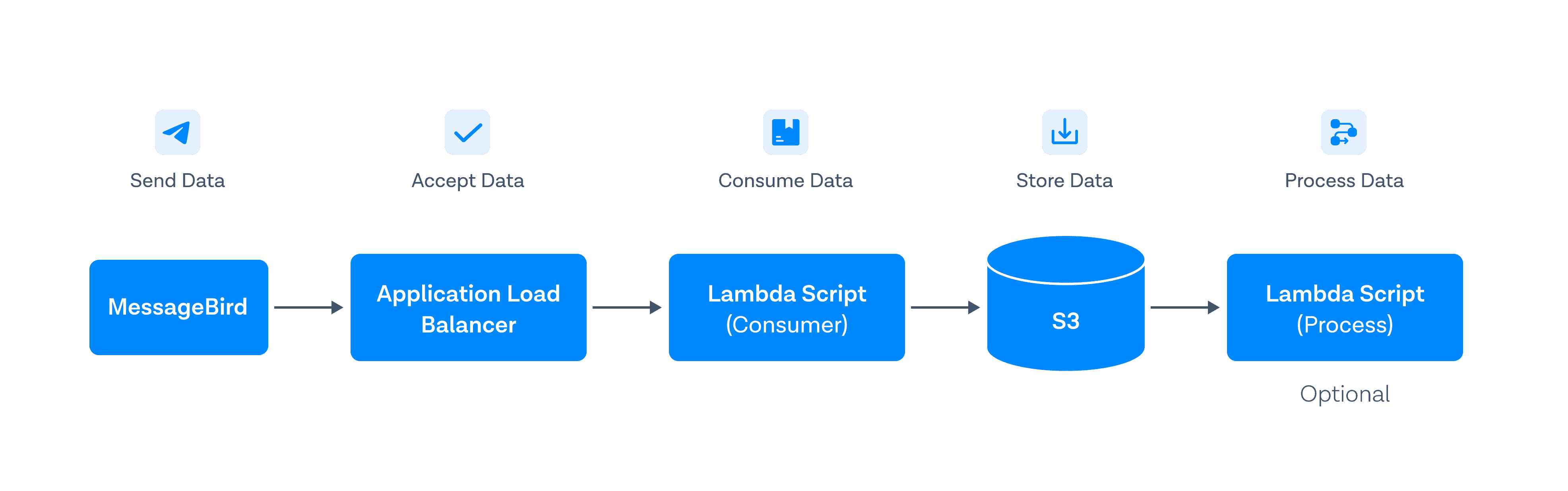
Component | Responsibility |
|---|---|
Bird Webhooks | Emit real-time event batches as HTTP POST requests |
Application Load Balancer | Receive external webhook traffic and route requests |
Lambda (Consumer) | Persist raw webhook batches to S3 efficiently |
Amazon S3 | Store batched event payloads as flat JSON files |
Lambda (Processor) | Transform or load stored data asynchronously |
To implement this workflow, let’s actually build them in the reverse order beginning with creating an S3 bucket where we will store our event data and then work backwards – adding each component that feeds into what we’ve built.
Create an S3 Bucket to Store the Webhook Data
Before creating our load balancer to accept the data, or our lambda function to store the data, we need to first create our S3 bucket where the data will be stored. While S3 provides excellent storage for webhook data, organizations also using PostgreSQL databases for event processing should implement proper backup and restore procedures to protect their structured data alongside their S3 storage strategy. To do this, navigate to the S3 service within AWS and press “Create Bucket.” You will be prompted to assign a name to your bucket and set the region – make sure to use the same region as your ALB and lambda function. When your S3 bucket is created, it will be empty – if you would like to organize the data inside of a folder, you can either create the intended directory now, or the directory will be created when your lambda function stores the file. In this example, we named our S3 bucket “bird-webhooks” and created a folder named “B Event Data” to store our event data – you will see these names referenced in our lambda function below.
Create a Lambda Function to Consume the Data
The actual processing and storage of the data will be performed by a lambda function that is invoked by our application load balancer (ALB).
The first step is to create your lambda function by navigating to the Lambda service within AWS and clicking “Create Function.” You will be prompted to assign a name to your lambda function and select which programming language to write your function in. For this example, we use Python as the runtime language.
Now we need to develop our lambda function. For a moment, let’s assume that our application load balancer has been configured and is forwarding the webhook payload to our lambda function – the lambda will receive a payload including the full headers and body. The payload is passed into our lambda function using the object “event” as a dictionary. You can reference the headers and the body of the payload independently by accessing the “headers” and “body” objects within the payload. In this example we are simply going to read the “x-messagesystems-batch-id” header, where the batch ID is a unique value created by Bird for the webhook batch, and use it as the filename when storing the body as a flat-file in S3; however, you may want to add additional functionality such as authentication checks or error handling, as needed.
When storing the payload to a flat-file on S3, we will need to define the name of the S3 bucket, location, and filename of the file where the payload data will be stored. In our sample lambda function, we do this within the “store_batch” function. In this example, we are going to store the entire batch as a single file, which helps to ensure that the data is collected and stored before the HTTP connection between Bird and your endpoint times out. While you could adjust the connection timeout settings on your load balancer, there are no guarantees that the connection won’t timeout on the transmission side (in this case Bird) or that the connection won’t be terminated before your lambda function finishes executing. It is a best practice to keep your consumer function as efficient as possible and reserve data processing activities for downstream processes where possible – such as converting the batched JSON-formatted payload into a CSV file, or loading the event data into a database.
It is important to note that you may need to update the permissions for your lambda function. Your execution role will need PutObject and GetObject permissions for S3. It is a best practice to enforce the principle of least privilege, so I recommend setting these permissions for only the S3 bucket where the webhook payloads will be stored.
A sample of our consumer lambda function can be found here.
As a quick note on the batch ID: Bird will batch events into a single payload, where each batch may contain 1 to 350 or more event records. The batch will be given a unique batch ID, which can be used to view the batch status by leveraging the Event Webhooks API or within your Bird account by clicking on a webhook stream and selecting “Batch Status.” In the event that a webhook payload could not be delivered, such as during a connection timeout, Bird will automatically retry the batch using the same batch ID. This can happen when your lambda function is running close to the max round-trip time of 10 seconds and is a reason for optimizing the consumer function to reduce execution time.
To handle all data processing activities, I recommend creating a separate lambda function that executes whenever a new file is created on the S3 bucket – this way, the data processing is performed asynchronously to the transmission of the data, and there is no risk of losing data due to a terminated connection. I discuss the processing lambda function in a later section.
Create an Application Load Balancer
In order to receive a webhook payload, we need to provide an endpoint to send the payloads to. We do this by creating an application load balancer within AWS by navigating to EC2 > Load Balancers and clicking “Create Load Balancer.” You will be prompted to choose which type of load balancer you want to create – for this, we want to create an application load balancer. We need to use an application load balancer (ALB) to build our consumer because the event webhooks will be sent as an HTTP request, and ALBs are used for routing HTTP requests within AWS. We could implement an HTTP Gateway as an alternative; however, we use an ALB for this project because it is more lightweight and cost-effective than HTTP Gateway. It’s important to note that if you choose to use an HTTP Gateway, the event format may be different than with an ALB, and therefore your lambda function will need to handle the request object accordingly.
Once your ALB has been created, you will be prompted to assign a name to your ALB and configure the scheme and access/security settings – since we plan to receive event data from an external source (Bird), we will want our ALB to be internet-facing. Under “Listeners and routing,” the ALB should listen to HTTPS on port 443, and we want to create a Target group that points to our lambda function so that our ALB will forward inbound requests to the consume lambda function we created above. You also need to ensure that the security group has permission to accept traffic through port 443.
Create a DNS Record for the Load Balancer
To make it easier for us to use our ALB as an endpoint, we will create an A record in DNS that points to our ALB. For this, we can use the AWS Route 53 service (or your current DNS provider) and create an A record for the hostname that you want to use for your endpoint (e.g. spevents.<your_domain>). When working with DNS at scale on AWS, be aware that there are undocumented DNS limits that can affect high-volume applications, especially those handling large amounts of outbound traffic like email delivery systems. The A record should be configured to point to the ALB we created. If you are using Route 53 to manage the DNS records, you can reference the ALB instance directly by enabling “Alias” and selecting the ALB; otherwise, if you are using an external DNS provider, you should point the A record to the public IP address of the ALB instance.
I recommend using a tool such as Postman to test that everything has been configured correctly before enabling your Bird webhook. You can make a POST request to your endpoint and confirm that a response is received. If your POST request does not return a response, you may need to double-check that your ALB is listening to the correct port.
Create a Bird Webhook
Now we are ready to create the webhook in Bird and use the hostname defined by the A record above as our target endpoint. To create the webhook, navigate to the Webhooks section within your Bird account and click “Create Webhook.” You will be prompted to assign a name for your webhook and provide a target URL – the target should be the hostname of the A record you created previously. Note that the target URL may require “HTTPS://” be included in the URL.
Once complete, verify the correct subaccount and events are selected, and press “Create Webhook” to save your configuration. The event data for all selected event types will now stream to our target URL and be consumed by our ALB for downstream processing.
Processing Webhook Event Data
Depending on the intended purpose for storing the Bird event data, your requirements may be satisfied by simply storing the JSON payload as a flat-file. You may also have a downstream ETL process already established that is capable of consuming and loading data in a JSON format. In both of these cases, you may be able to use the flat-file created by our processing lambda that we created above as-is.
Alternatively, you may need to transform the data – such as to convert from a JSON to a CSV format – or load the data directly into a database. In this example, we will create a simple lambda function that will convert the webhook data from the original JSON format into a CSV file that could be loaded into a database.
Create a Lambda to Process the Data
As with the lambda function to consume the webhook data, we need to create a new lambda function by navigating to the Lambda service within AWS and pressing “Create Function.” This new lambda function will get triggered when a new file is created on our S3 bucket – it will read the data and convert it into a new csv file.
The lambda function accepts the file information as an event. In the sample lambda function, you will see that we first have a series of validation checks to ensure that the data is complete and formatted as expected. Next, we convert the JSON payload into a CSV file by using the “csv” library and writing to a temp file. Lambda functions are only able to write local files to the “/tmp” directory, so we create a temporary csv file and name it with the convention <batch_id>.csv. The reason we use the batch_id here is simply to ensure that any parallel processes that are running as a result of receiving multiple webhook payloads will not interfere with each other, as each webhook batch will have a unique batch_id.
Once the data has been fully converted to CSV, we read the CSV data as a byte stream, delete the temp file, and save the CSV data as a new file on S3. It is important to note that a different S3 bucket is needed for the output, otherwise, we risk creating a recursive loop that can result in increased lambda usage and increased costs. We will need to identify in which S3 bucket and location we want our CSV file to be stored within our lambda function. Follow the same procedure as above to create a new S3 bucket to store our CSV file.
Note that the tmp directory is limited to 512 MB of space, so it is important that the temp file is deleted afterward to ensure sufficient space for future executions. The reason we use a temp file, as opposed to writing directly to S3, is to simplify the connection to S3 by having a single request.
Just as with the consume lambda function, you may need to update the permissions for your process lambda function. This lambda function requires the execution role to have GetObject permissions for the input S3 bucket, and both PutObject and GetObject for the output S3 bucket.
A sample of our processing lambda function can be found here.
Configure a Lambda to Execute When New Data is Stored on S3
Now that our lambda function to convert the file from JSON to CSV format has been created, we need to configure it to trigger when a new file is created on our S3 bucket. To do this, we need to add a trigger to our lambda function by opening our lambda function and clicking “Add Trigger” at the top of the page. Select “S3” and provide the name of the S3 bucket where the raw webhook payloads are stored. You also have the option to specify file prefix and/or suffix to filter on. Once the settings have been configured, you can add the trigger by clicking “Add” at the bottom of the page. Now your processing lambda function will execute whenever a new file is added to your S3 bucket.
Loading the Data into a Database
In this example, I will not cover loading the data into a database in detail, but if you have been following along with this example you have a couple of options:
Load the data directly into your database within your processing lambda function
Consume your CSV file using an established ETL process
Whether you’re using an AWS database service, such as RDS or DynamoDB, or you have your own PostgreSQL database (or similar), you can connect to your database service directly from your process lambda function. For instance, in the same way, that we called the S3 service using “boto3” in our lambda function, you could also use “boto3” to call RDS or DynamoDB. The AWS Athena service could also be used to read the data files directly from the flat-files, and access the data using a query language similar to SQL. I recommend referring to the respective documentation for the service you are using for more information on how best to accomplish this within your environment.
Similarly, there are many services available that can help consume CSV files and load the data into a database. You may already have an established ETL process that you can leverage.
We hope you found this guide to be helpful – happy sending!



